Abstract
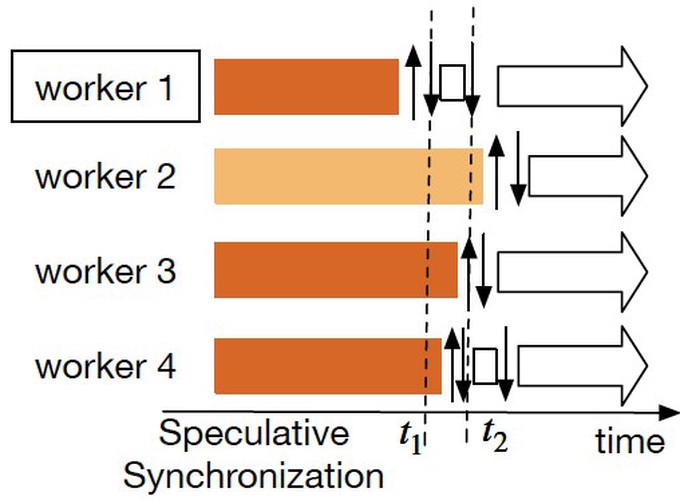
Large machine learning models are typically trained in parallel and distributed environments. The model parameters are iteratively refined by multiple worker nodes in parallel, each processing a subset of the training data. In practice, the training is usually conducted in an asynchronous parallel manner, where workers can proceed to the next iteration before receiving the latest model parameters. While this maximizes the rate of updates, the price paid is compromised training quality as the computation is usually performed using stale model parameters. To address this problem, we propose a new scheme, termed speculative synchronization. Our scheme allows workers to speculate about the recent parameter updates from others on the fly, and if necessary, the workers abort the ongoing computation, pull fresher parameters, and start over to improve the quality of training. We design an effective heuristic algorithm to judiciously determine when to restart training iterations with fresher parameters by quantifying the gain and loss. We implement our scheme in MXNet—a popular machine learning framework—and demonstrate its effectiveness through cluster deployment atop Amazon EC2. Experimental results show that speculative synchronization achieves up to 3x speedup over the asynchronous parallel scheme in many machine learning applications, with little additional communication overhead.