Abstract
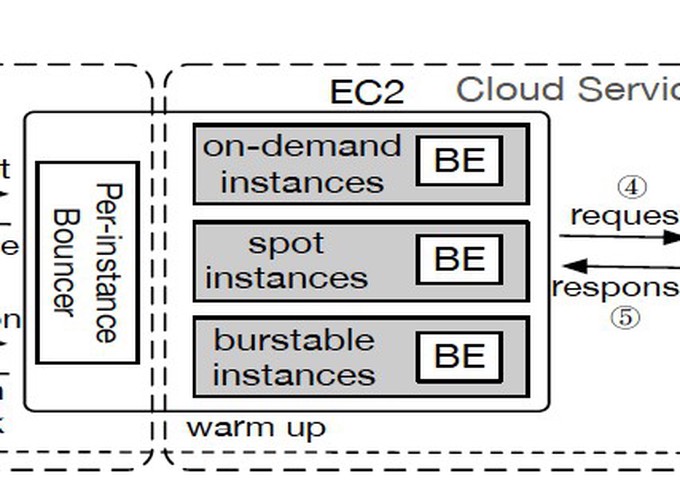
The remarkable advances of Machine Learning (ML) have spurred an increasing demand for ML-as-a-Service on public cloud - developers train and publish ML models as online services to provide low-latency inference for dynamic queries. The primary challenge of ML model serving is to meet the response-time Service-Level Objectives (SLOs) of inference workloads while minimizing serving cost. In this paper, we proposes MArk (Model Ark), a general-purpose inference serving system, to tackle the dual challenge of SLO compliance and cost effectiveness. MArk employs three design choices tailored to inference workload. First, MArk dynamically batches requests and opportunistically serves them using expensive hardware accelerators (e.g., GPU) for improved performance-cost ratio. Second, instead of relying on feedback control scaling or over-provisioning to serve dynamic workload, which can be too slow or too expensive, MArk employs predictive autoscaling to hide the provisioning latency at low cost. Third, given the stateless nature of inference serving, MArk exploits the flexible, yet costly serverless instances to cover occasional load spikes that are hard to predict. We evaluated the performance of MArk using several state-of-the-art ML models trained in TensorFlow, MXNet, and Keras. Compared with the premier industrial ML serving platform SageMaker, MArk reduces the serving cost up to 7.8 tiimes while achieving even better latency performance.